���ڙz���������ɵĶ�ģ�K�˹����ܽ������U֧��ϵ�y���������������c�Ñ��w�Ą��¿��
��Scientific Reports����A multi module a.i. system for intelligent health insurance support using retrieval augmented generation
�����w��
��
��
С
��
�r�g��2025��12��05��
��Դ��Scientific Reports 3.9
�����]��
�������Ľ�B��һ�ᘌ��������U�I����s���������y�}�Ą����о������Q���U�l��ޝ��y�����Ñ��Q�����y�Ȇ��}���о��ˆT�_�l��һ���ڙz���������ɣ�RAG���Ķ�ģ�KAIϵ�y��ԓϵ�y�����˱��U����C���ˡ��������]������ęn�z�������ܣ�ͨ�^�I���m�����Z�xǶ���FAISS�����z�����g�����F���������]�����ʣ�Hit@5=1.0�����Z�xƥ�䣨BERTScore F1=0.84���ă������F���e������u������ģ�K���Ԅ��u���؏��|�����@�������˴��Z��ģ�͵Ļ��X�L�U���鱣�U�ИI�����ܻ������ṩ���·�ʽ��
����
���t���M�ó��m�ϝq�Į��£��������U�ѳɞ邀�˺ͼ�ͥ���������L�U����Ҫ���ϡ�Ȼ����ӡ�ȣ��M�܌�ʩ��Ayushman Bharat���ش��l��Ӌ��������2024�����мs7�|�˛]�н������U���w������@�N����ȱ�ڵ�һ����Ҫԭ���DZ��U���ߵď��s�ԡ������U��ͬ��M���g�g�Z�͏��s�~�R����ͨ���M���y�����⡣�@�N���ȵ�ȱ������Ͷ���˽����`�Ᵽ�Ϸ��������t���o����r�����R������Ը��M�á�
���������_���ǣ��Ј��ϴ��ڱ��ౣ�UӋ����ÿ�N���в�ͬ�ėl��͗l�����@ʹ�����M�ߎ��������������ǛQ�ߡ��mȻ�˹����ܣ�AI������Ȼ�Z��̎����NLP�����g�ڽ������U�I��đ��Þ��Q�@Щ���}�ṩ�˿��ܣ����F��ϵ�y��������Ԓ�f�����������]���ęn�z��ҕ�骚���΄գ�ȱ���yһ�ܘ���
����ӡ������Symbiosis���g�о������о��F��ڡ�Scientific Reports���ϰl����һ헄����о��������һ�N���ڙz���������ɣ�RAG���Ķ�ģ�KAIϵ�y�����T�������ܽ������U֧�֡��@һϵ�y�ɹ���������ģ�K�������U��������C���ˡ����Ի��������]����������ęn�z��ϵ�y�������ϵ���һ�ܘ��У��@�������˱��U��Ϣ�Ŀɼ��Ժ����ȡ�
�о��ˆT������һ��������������ģ�K�Ľyһ��ܣ����U����C����̎��һ���ԃ���������]����ʹ��RAG�ܘ��Y�ϽY�����ͷǽY�������ߔ������ęn�z��ģ�K֧�֏��ς������Ќ��F�l��������P�I�������������u��������ģ�M����Д������P�ԡ��ʴ_�ԡ������Ⱥ͎������Ă��S���u���؏��|�����γ��Ԅӻ�����ѭ�h�����g���İ�����ʹ��Sentence Transformer�����Z�xǶ�룬FAISS�M�и�Ч�����z����LLaMA 3��DeepSeek R1��������ģ�ͣ��Լ�����BERTScore��ROUGE-L�ȶ�ָ�˵�ȫ���u���wϵ��
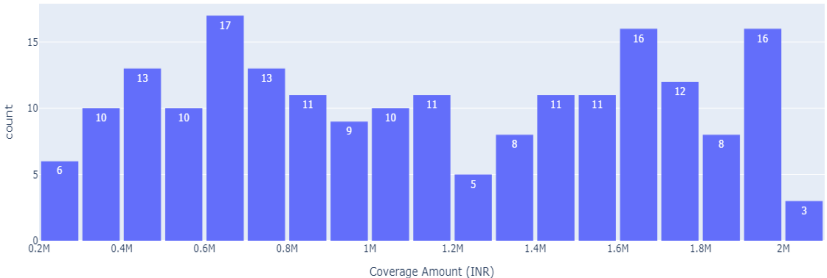
�������]ģ�K����RAG�ܘ�������ͨ�^���������˰���1,000�lģ�M�挍���U����ӛ䛵ĺϳɔ�������ԓ���������w������ID�����U��˾���aƷ��͡����Ͻ��~��Ͷ���˔�����ȱ��M��14���Y����������������߉�ֶ��g�����ه�ԣ�ģ�M�挍������r��
�о��ˆTʹ��all-MiniLM-L6-v2�����D�Qģ�͌��ı���������ӳ����ܼ�������Ȼ��ͨ�^FAISS��Facebook AI�������������콨�����������������������@�N�OӋʹ���Z�x���Ƶ��������������g�б˴˽ӽ����Ķ��܉��Ч�ٻ��c�Ñ���ԃ�����P�����ߡ�
�u���Y���@ʾ��ԓϵ�y��10�����ӻ����U���P��ԃ�Ĝyԇ�б��F��ɫ��Hit@5�_��1.0�����в�ԃ���ɹ��z��������һ�����P���ԣ���Recall@5��0.833��NDCG@5��0.69���M��Precision@5�����^�ͣ�0.333�������Z�x�u���@ʾBERTScore F1���_0.84���������ɻ؏��c���������Z�����Z�x�Ϸdz��ӽ���
���U����C���˵����܆�������
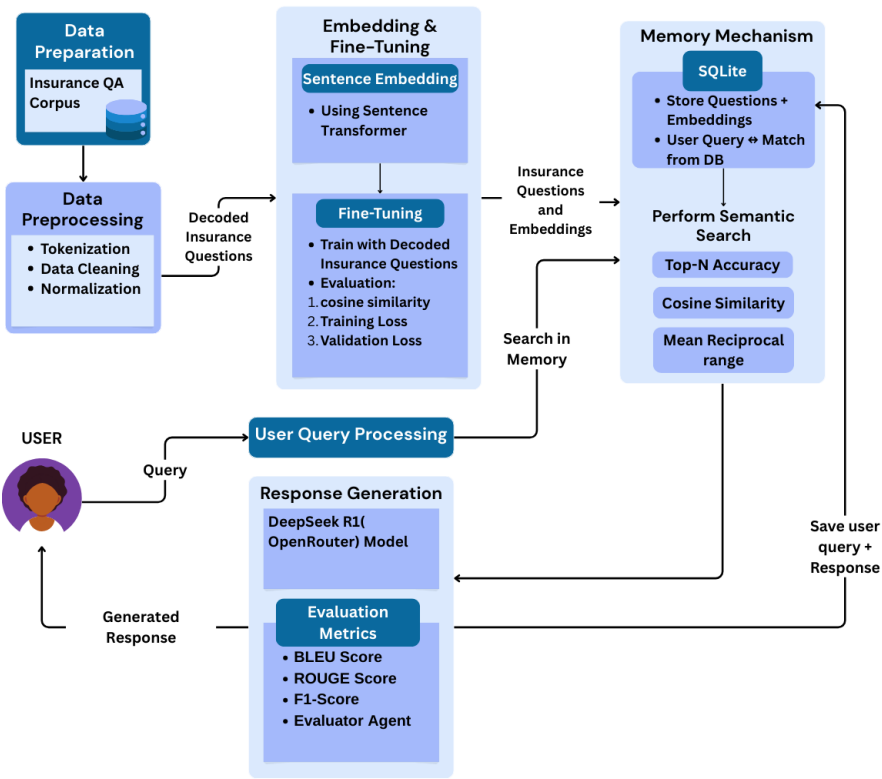
���U����C����ģ�K���ö��A����Ȼ�Z��̎�����̣���Insurance QA�Z�ώ����A��ԓ�Z�ώ�������U�I����挍���熖�}��ϵ�yͨ�^�AӖ����Sentence Transformer��ݔ�놖�}�D�Q���ܼ�������ʾ�����惦��SQLite���������Ԍ��F��Ч�z����
ԓϵ�y֧���Z�����ı�ݔ�룬����ӛ���C�ƣ��܉�z���vʷ����ӛ䛡����Ñ�����²�ԃ�r��ϵ�y���ȇLԇͨ�^Ƕ���������M��ӛ�����������oƥ��t�D������������ƶȵ��Z�x��������K푑�ͨ�^OpenRouterƽ�_�ϵ�DeepSeek R1�Z��ģ�����ɣ����惦�Ԃ�δ���ٻء�
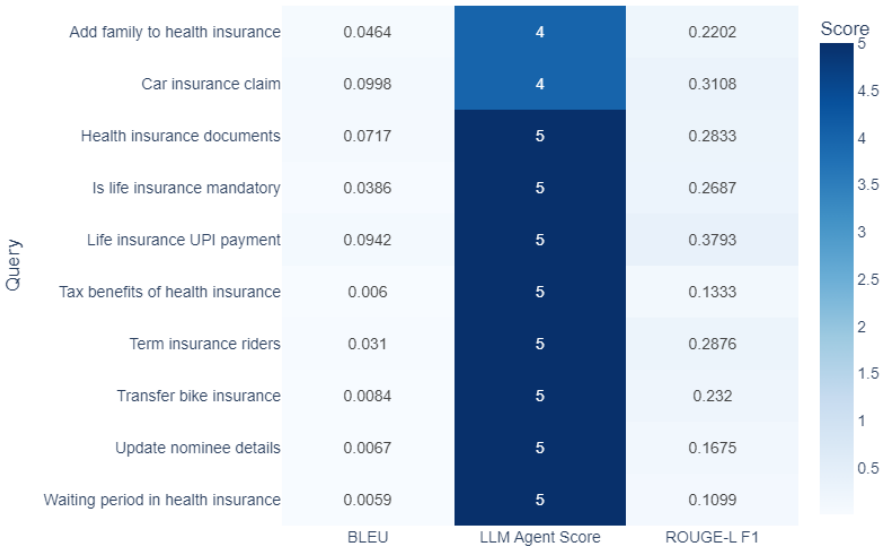
�u���Y���������mȻBLEU�֔��^�ͣ��������o׃���^����ROUGE-L F1�֔��еȣ���LLM�����u�ָ��_4-5�֣��M��5�֣����C��ϵ�y�ܳ��m����Ȼ��Ԓ��ʽ�ṩ���_��Ϣ��
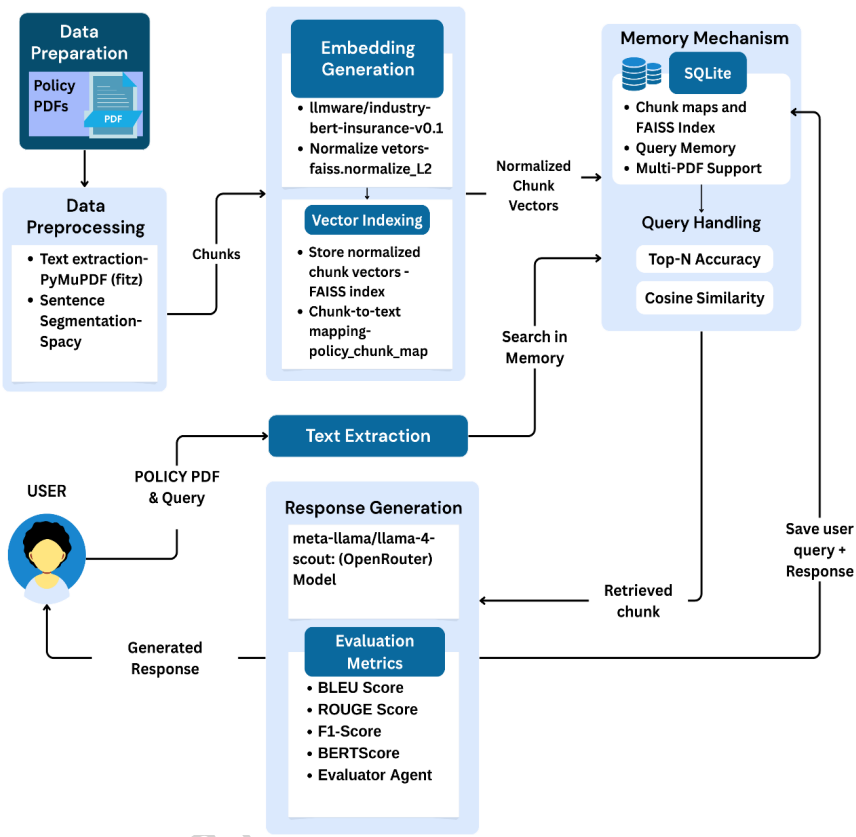
�����ęn�z��ģ�K֧���Ñ��ς�PDF��ʽ�ı��U�����ļ�����ͨ�^PyMuPDF����ȡ�ı����ݡ��ı���SpaCy NLP��־���M�ϳ��Z��һ�µĉK��Ȼ��ͨ�^�I���ض����D�Qģ��llmware/industry-bert-insurance-v0.1����������Ƕ�롣
�@ЩǶ��������L2�wһ�������FAISS������IndexFlatIP�������F���ڃȷeӋ��Ŀ����������������Ñ���ԃ����ͬģ�;��a���cFAISS�����Ȍ��ҵ������ƵĉK�������meta-llama/llama-4-scoutģ���������������ժҪ�ͽ�ጡ�
�u�������@ʾ��ԓģ�K��BERTScore F1�_��0.8443���������ɻ؏��c�������g���Џ�����Z�x���R�ԣ��M�ܴ��o���ܲ�ͬ��������Ч�����x��
���о���һ��ͻ���������������u������������RAG����ѭ�h�е������u���C�ơ�ԓ����ʹ�ô��Z��ģ���ӵ��u���˜ʣ������P�ԡ��ʴ_�ԡ������Ⱥ͎������Ă��S���u�����ɻ؏ͣ�ģ�M��������Дࡣ
�u���������H�ṩ�������ܜy����߀�������Ҽm���ķ����M�������Sϵ�y�����О�ĵ����������o����m�˹��O�����@�N�Ԅӻ��|�������^�̴��������u���I���m��LLMϵ�y�OӋ�е��·������¡�
ԓ�о��ĺ���ؕ�I���������һ���yһ�Ķ�ģ�K�ܘ�������Ԓ���𡢂��Ի��������]�͗l��ęn�z�����������ϵ����z�����ɿ���С��c��������̎���@Щ�΄յČ��F��ͬ��ԓϵ�yͨ�^����Ƕ��ͻ���FAISS��ͨ�Ùz�����ɣ����F�˿�ģ�K���Z�xһ���Ժ͔������á�
�ڼ��g���棬�о��_�l�ˌ��Tᘌ��������U��Ϣ�������I���m���z���������ɹܵ���ʹ�û���Transformer�ľ���Ƕ����InsuranceQA�Z�ώ���I���ض��Ľ��������ı����M���{���Ķ��܉���ʴ_�ؙz���Z�x���P�ėl��������x헡�
�ڌ��H���Ì��棬�Ñ��yԇ�@ʾ15�����c�ߵĝM����_89%��푑����t����1.8�룬�C����ϵ�y���r����Ŀ����ԡ�ϵ�y����ֱ�^���ã��Ñ��ɸ�����Ҫ�x���ęn�������������]���c���U����C���ˌ�Ԓ��
�@��о�ͨ�^�ϳ��Z�x�z�������Z�����ɺ��u���ӷ������鱣�U���ܱO�ܡ��ļ��ܼ����I��Ĕ��ַ��ս����˿ɔUչ���·�ʽ���о��Y����C��RAG�Ӽܘ��ڱ��U���I�����Ч�ԣ��������ʴ_�ԺͿɽ�������P��Ҫ��δ�������������ڽY���挍�ͺϳɔ����Ļ�ϔ����������Mһ������ϵ�y�����ԣ�����ԓ��ܔUչ�����ɺ�ͬ���y�к��t�����߽��x�������I��
 ����ͨ�Ź���̖
����ͨ�Ź���̖
 ����ͨ������
����ͨ������
- ����
- ���H
- ����
- ����
- �a�I
- ���c
- ����
���ՄӑB |
�˲��Ј� |
�¼��g���� |
�Ї��ƌW�� |
��չ�_ |
BioHot |
���v��ֱ�� |
��չ���� |
�r���� |
���g��Ӎ |
���Mԇ��
������� ����ͨ
Copyright© eBiotrade.com, All Rights Reserved
ϵ���䣺
��ICP��09063491̖